Recovery¶
This guide covers operational recovery for Azure Functions: rollback, backup planning, and regional resilience. It focuses on practical runbook execution for minimizing downtime and data loss.
Platform Guide
For scaling architecture and plan comparison, see Scaling.
Language Guide
For Python deployment specifics, see the Python Tutorial.
Prerequisites¶
Prepare these baseline capabilities before an incident:
- Azure CLI installed and authenticated with rights to the target subscription.
- Release artifacts stored in immutable storage with version identifiers.
- Monitoring available in Application Insights or Log Analytics.
- Documented RTO and RPO values approved by service owners.
- Primary and secondary region deployments provisioned with infrastructure as code. Use consistent variable names in all runbooks:
| Command/Parameter | Purpose |
|---|---|
RG_PRIMARY | Resource group for the primary region |
RG_SECONDARY | Resource group for the secondary region |
APP_PRIMARY | Function app name in the primary region |
APP_SECONDARY | Function app name in the secondary region |
STORAGE_ARTIFACTS | Storage account for build artifacts |
TM_PROFILE | Traffic Manager profile name |
FD_PROFILE | Front Door profile name |
HEALTH_PATH | API path for health checks |
Portal Walkthrough¶
This section shows portal blades relevant to recovery operations for a live Function App (Consumption Y1, Korea Central). PII is masked.
Deployment Center Blade¶
[Observed] The Deployment Center blade shows the deployment source configuration. The Source dropdown allows selecting CI/CD providers (GitHub Actions, Azure DevOps, etc.) for automated deployment and rollback:
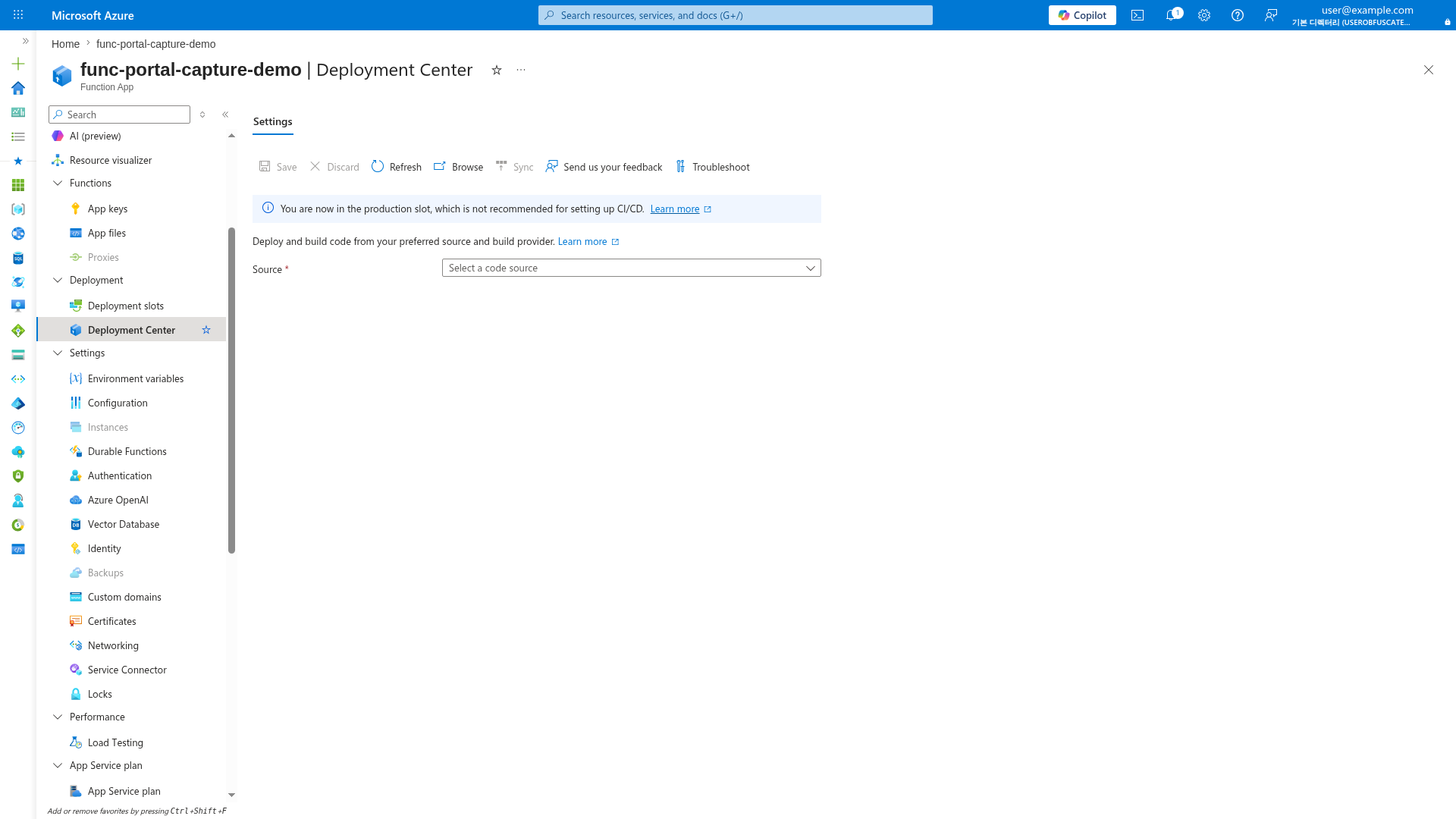
[Inferred] For fast rollback during incidents, configure a deployment source and use deployment slots (Premium/Dedicated). On Consumption, rollback requires redeploying a previous artifact version via CI/CD pipeline. Keep release artifacts in immutable storage with version identifiers for reliable rollback.
Function App Overview¶
[Observed] The Overview blade shows the runtime status, plan details, and function list. The Stop and Restart buttons in the toolbar provide emergency controls during incidents:
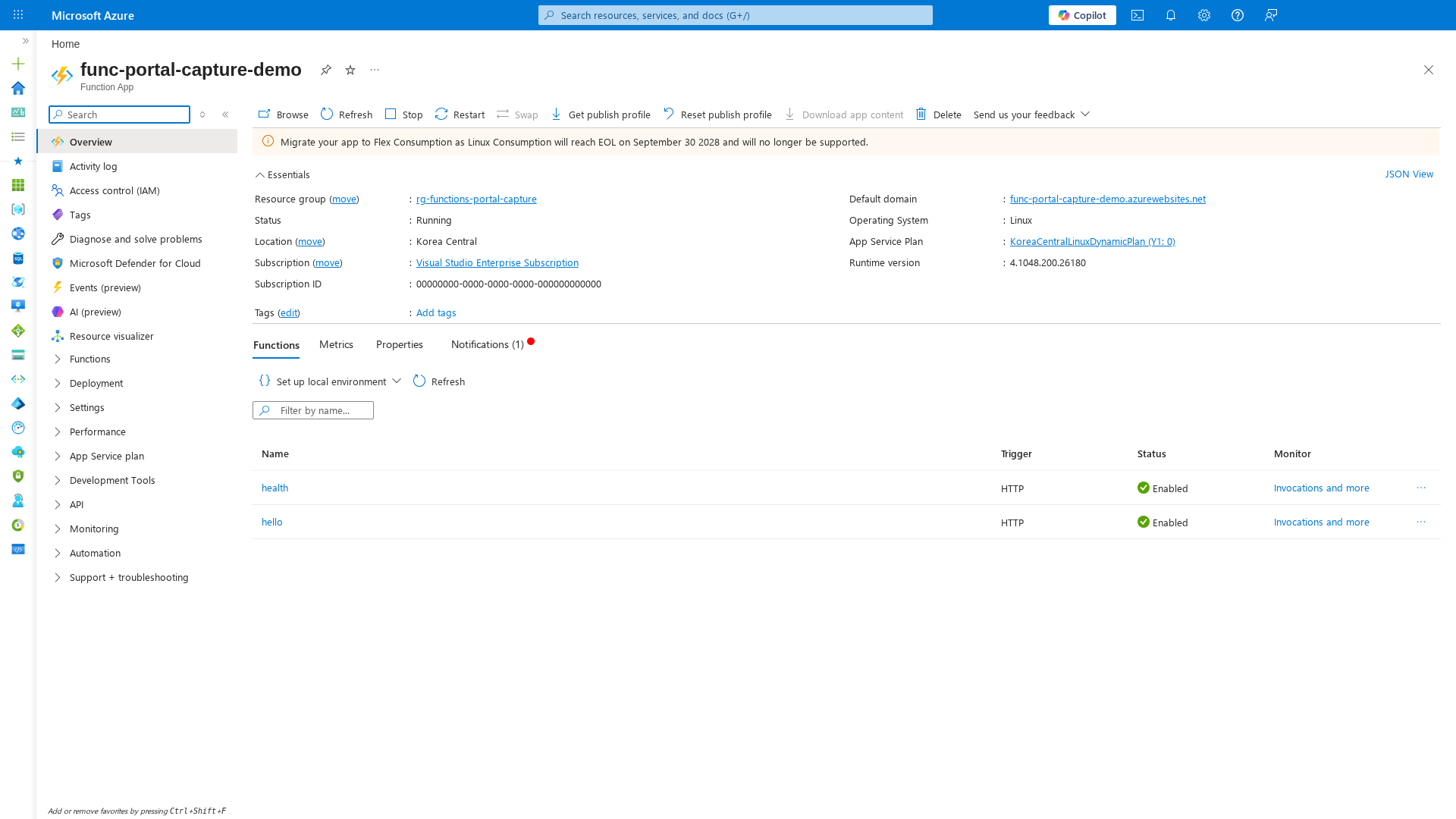
[Inferred] During recovery, verify function status (Enabled/Disabled) and runtime version after rollback. The "Stop" button can be used as an emergency circuit breaker to halt all executions during cascading failures, but note that on Consumption plans, stopping and restarting may incur cold-start delays.
Activity Log Blade¶
[Observed] The Activity log shows timestamped control-plane operations, useful for correlating deployment events with incidents:
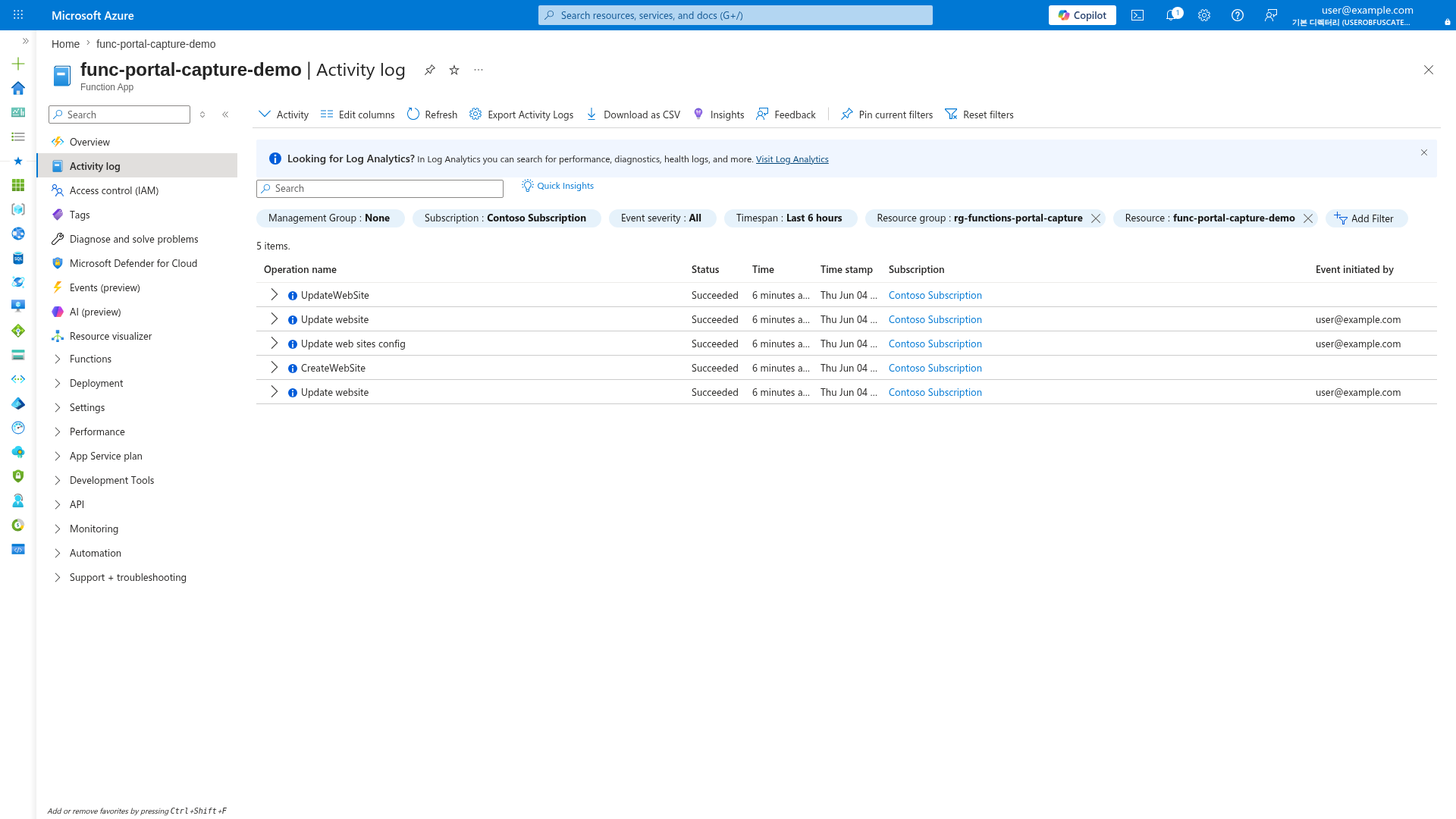
[Inferred] During recovery, check the Activity log to identify what changed before the incident started. Filter by Timespan to narrow the window around the failure onset.
When to Use¶
Use rollback, failover, or rebuild based on blast radius and dependency health.
Rollback¶
Rollback is the default for deployment-induced incidents where infrastructure is healthy. - Trigger condition: elevated failures begin right after a release. - Typical scope: single app, single region, no regional dependency outage. - Expected speed: minutes (fastest option when slots are available).
Failover¶
Failover is preferred when region-level or shared dependency instability affects availability. - Trigger condition: sustained platform or dependency failures in the primary region. - Typical scope: multiple apps or critical dependencies in one geography. - Expected speed: minutes to tens of minutes based on DNS and warm capacity.
Rebuild¶
Rebuild is used when both deployment state and environment integrity are uncertain. - Trigger condition: configuration drift, corrupted runtime state, or failed rollback attempts. - Typical scope: app plus supporting resources requiring controlled rehydration. - Expected speed: longer; prioritize data consistency and security posture.
Recovery objectives¶
Define service objectives before incidents occur:
- RTO (Recovery Time Objective): target time to restore service.
- RPO (Recovery Point Objective): acceptable data loss window. RTO and RPO determine architecture, replication, and operational tooling.
Procedure¶
Use the runbook that matches observed symptoms and dependency status.
Recovery decision flow¶
Use this decision path to choose rollback, failover, or rebuild.
flowchart TD
A[Incident detected] --> B[Assess scope and impact]
B --> C{Deployment related?}
C -->|Yes| D{Slots available and healthy dependencies?}
D -->|Yes| E[Rollback via slot swap]
D -->|No| F[Redeploy last known good artifact]
C -->|No| G{Regional or shared dependency issue?}
G -->|Yes| H[Execute regional failover]
G -->|No| I[Rebuild app or infra component]
E --> J[Verify health and SLOs]
F --> J
H --> J
I --> J
J --> K{Recovery validated?}
K -->|Yes| L[Close incident and start follow-up]
K -->|No| M[Escalate and run next strategy]Scenario A: deployment regression with slots available¶
- Confirm release timing aligns with error spike.
- Validate staging slot is last known good version.
- Run slot swap rollback.
- Execute health checks and smoke tests.
- Pause further releases until root cause is documented.
For Premium and Dedicated plans, deployment slots are the fastest rollback path.
az functionapp deployment slot swap \
--resource-group "$RG_PRIMARY" \
--name "$APP_PRIMARY" \
--slot staging \
--target-slot production
| Command/Parameter | Purpose |
|---|---|
az functionapp deployment slot swap | Swaps the staging slot with the production slot |
--resource-group "$RG_PRIMARY" | Specifies the primary resource group |
--name "$APP_PRIMARY" | Specifies the function app name |
--slot staging | The source slot for the swap |
--target-slot production | The destination slot for the swap |
Example output:
{
"changed": true,
"name": "func-orders-prod-krc",
"resourceGroup": "rg-functions-prod-krc",
"slotSwapStatus": {
"sourceSlotName": "staging",
"destinationSlotName": "production",
"timestampUtc": "2026-04-04T09:11:23Z"
},
"status": "Succeeded"
}
Scenario B: deployment regression without slots¶
- Identify immutable artifact version to restore.
- Redeploy artifact with
config-zip. - Re-apply known-good settings baseline if drift is detected.
- Restart function app if runtime remains unhealthy.
- Validate queue/trigger processing catch-up.
For plans without slot support, redeploy the last known good artifact.
az functionapp deployment source config-zip \
--resource-group "$RG_PRIMARY" \
--name "$APP_PRIMARY" \
--src "/tmp/orders-api-2026.03.28.zip"
| Command/Parameter | Purpose |
|---|---|
az functionapp deployment source config-zip | Redeploys a specific zip artifact to the function app |
--src | Path to the known-good artifact zip file |
Example output:
{
"active": true,
"author": "<deployment-identity>",
"complete": true,
"deployer": "az_cli_functions",
"id": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"lastSuccessEndTime": "2026-04-04T09:18:44Z",
"message": "Deployment successful",
"status": 4
}
Artifact and configuration backup¶
Maintain these backups for every release:
- Immutable build artifact with version metadata.
- Infrastructure templates and parameter sets.
- Exported app settings baseline (with secret values protected).
- Runbook steps for redeploy and validation. Keep backup assets in secured, versioned storage.
Data and state resilience¶
Most Azure Functions apps depend on storage and messaging services for state. Recovery depends on those services' durability configuration:
- Use geo-redundant options where business continuity requires cross-region resilience.
- Align queue/topic retention and replay capability with RPO targets.
- Protect durable workflow state with storage redundancy and backup policy.
Scenario C: regional outage or severe dependency instability¶
- Confirm primary region dependency or platform degradation.
- Verify secondary region app and dependencies are healthy.
- Trigger Traffic Manager or Front Door failover action.
- Monitor client success rate and latency during convergence.
- Update incident channel with effective failover time.
Regional recovery planning¶
Region-level recovery usually requires pre-provisioned secondary environment. Recommended pattern:
- Provision primary and secondary environments with infrastructure as code.
- Replicate critical configuration and secrets strategy.
- Use traffic management or DNS failover process.
- Exercise failover and failback drills on a schedule.
Multi-region failover architecture:
flowchart TD
U[Clients] --> E[Edge Routing]
E --> TM[Traffic Manager or Front Door]
TM --> P[Primary Region Function App]
TM --> S[Secondary Region Function App]
P --> SP[(Primary Storage)]
S --> SS[(Secondary Storage)]
P --> AP[(Application Insights)]
S --> AP
AP --> O[Operations Dashboard]Concrete failover patterns:
- Traffic Manager Priority Routing
- Configure endpoint priority: primary =
1, secondary =2. - Use endpoint monitoring path aligned to app health endpoint.
- Keep DNS TTL low enough for acceptable failover convergence.
- Configure endpoint priority: primary =
- Front Door Origin Group Failover
- Place both regional function origins in one origin group.
- Configure health probes with low interval for faster detection.
- Use weighted or priority routing based on active-passive vs active-active.
Traffic Manager example:
az network traffic-manager endpoint update \
--resource-group "$RG_PRIMARY" \
--profile-name "$TM_PROFILE" \
--type azureEndpoints \
--name primary-endpoint \
--endpoint-status Disabled
| Command/Parameter | Purpose |
|---|---|
az network traffic-manager endpoint update | Updates an endpoint in the Traffic Manager profile |
--profile-name "$TM_PROFILE" | Target Traffic Manager profile |
--name primary-endpoint | Name of the endpoint to update |
--endpoint-status Disabled | Disables the primary endpoint to force failover to secondary |
Example output:
{
"endpointStatus": "Disabled",
"name": "primary-endpoint",
"priority": 1,
"targetResourceId": "/subscriptions/<subscription-id>/resourceGroups/rg-functions-prod-krc/providers/Microsoft.Web/sites/func-orders-prod-krc",
"type": "Microsoft.Network/trafficManagerProfiles/azureEndpoints"
}
Front Door example:
az afd origin update \
--resource-group "$RG_PRIMARY" \
--profile-name "$FD_PROFILE" \
--origin-group-name "functions-origins" \
--origin-name "origin-primary" \
--enabled-state Disabled
| Command/Parameter | Purpose |
|---|---|
az afd origin update | Updates an origin within the Front Door profile |
--origin-group-name | Target origin group |
--origin-name "origin-primary" | Name of the primary origin to update |
--enabled-state Disabled | Disables the primary origin to force traffic to others in the group |
Scenario D: rebuild from clean infrastructure baseline¶
- Freeze change pipeline and snapshot forensic evidence.
- Deploy infrastructure templates into clean target scope.
- Deploy last known good application artifact.
- Restore non-secret configuration and key vault references.
- Run full verification checklist before reopening traffic.
Health-based decision gates¶
Before failover or rollback, validate:
- Current incident scope (app-only or dependency-wide).
- Secondary environment readiness.
- Data consistency and queue lag status.
- Alert suppression or rerouting during controlled switch.
Verification¶
After recovery action:
- Confirm health endpoint and key user journeys.
- Verify failure rate and latency return to baseline.
- Validate message processing catch-up.
- Re-enable normal alert thresholds and dashboards.
Health check verification command:
| Command/Parameter | Purpose |
|---|---|
az rest --method get | Sends an authenticated GET request to the health endpoint |
--url | The full URL of the function app health check |
Example output:
{
"checks": {
"application": "Healthy",
"storage": "Healthy",
"queue": "Healthy"
},
"durationMs": 38,
"status": "Healthy",
"timestampUtc": "2026-04-04T09:22:10Z",
"version": "2026.03.28"
}
Rollback / Troubleshooting¶
If recovery does not stabilize service, apply these controls. - Revert traffic decision and isolate failing component path. - Compare app settings and connection references between regions. - Check dependency health (storage, messaging, downstream APIs) before app-level retries. - Review deployment history and pin known-good release hash. - Escalate to platform support for region-level anomalies.
Advanced Topics¶
Recovery drill checklist¶
- Documented owner and escalation path.
- Tested rollback command set.
- Tested region failover procedure.
- Measured achieved RTO/RPO versus targets.
- Action items tracked for gaps found during drill.