Performance Degradation¶
1. Summary¶
This playbook applies when an Azure App Service app becomes slow, latency rises, throughput drops, or CPU and memory behavior degrade under load or after a release. Use it when the site still responds but users experience timeouts, slow APIs, queueing, or intermittent 5xx errors tied to resource pressure.
Symptoms¶
- Requests that normally finish in milliseconds now take seconds.
- P95 or P99 latency spikes while request volume stays similar.
- CPU or memory rises and the app becomes unstable or restarts.
- The app serves intermittent
500,502,503, or504responses during busy periods.
Common error messages¶
The request timed out.502 Bad Gateway,503 Service Unavailable, or504 Gateway Timeout.OutOfMemory, worker recycle, or repeated restart messages.SNAT exhaustion-style dependency failures that look like app slowness.
flowchart TD
A[Performance degradation reported] --> B{Is latency high for all routes?}
B -->|No| H1[H1: One endpoint or dependency regressed]
B -->|Yes| C{Is CPU saturated?}
C -->|Yes| H2[H2: CPU bottleneck or insufficient scale]
C -->|No| D{Is memory growing or workers restarting?}
D -->|Yes| H3[H3: Memory pressure or garbage-collection stress]
D -->|No| E{Are dependencies failing or slow?}
E -->|Yes| H4[H4: Downstream dependency or outbound issue]
E -->|No| F[Check cold start, disk pressure, and recent release changes]2. Common Misreadings¶
| Observation | Often Misread As | Actually Means |
|---|---|---|
| CPU is low but requests are slow | App Service is underutilized and healthy | Latency can come from downstream waits, thread starvation, lock contention, or SNAT issues. |
| Memory is high | App definitely has a leak | Some runtimes reserve memory aggressively; correlate with restart behavior and request latency. |
503 appears during load | Networking outage only | The app may be overloaded, restarting, or not accepting requests fast enough. |
| One slow route dominates user complaints | Whole platform is degraded | Path-specific code or one dependency may be the real bottleneck. |
| Scaling out helped briefly | Root cause is fixed | Scale can mask but not remove inefficient code, hot paths, or memory churn. |
3. Competing Hypotheses¶
| Hypothesis | Likelihood | Key Discriminator |
|---|---|---|
| H1: One endpoint, query, or code path regressed | High | Slowest requests cluster on a small set of URIs or operations. |
| H2: CPU saturation or insufficient worker capacity | High | CPU trend and latency/error trend rise together during demand spikes. |
| H3: Memory pressure or worker degradation | High | Memory climbs, response times worsen, and restarts or recycling appear. |
| H4: Downstream dependency or outbound networking issue | Medium | Dependency calls fail or slow while app CPU remains relatively low. |
| H5: Release introduced cold-start or configuration regression | Medium | Symptoms begin exactly after deployment or instance movement. |
4. What to Check First¶
-
Confirm app state and plan relationship
-
Inspect autoscale or instance count context if applicable
-
Review startup and runtime settings that influence performance behavior
-
If a release just occurred, inspect recent deployment history
5. Evidence to Collect¶
Use one shared incident window across HTTP logs, console/platform logs, and Application Insights requests or dependencies if available.
5.1 KQL Queries¶
Query 1: Request latency and error trend¶
AppServiceHTTPLogs
| where TimeGenerated > ago(24h)
| summarize Requests=count(), Errors=countif(ScStatus >= 500), P95=percentile(TimeTaken, 95), P99=percentile(TimeTaken, 99) by bin(TimeGenerated, 5m)
| order by TimeGenerated asc
| Column | Example data | Interpretation |
|---|---|---|
Requests | 6200 | Shows whether demand increased materially. |
Errors | 180 | Rising errors with rising latency suggest saturation or dependency failure. |
P95 | 2800 | Main symptom metric for user pain. |
P99 | 9200 | Tail latency helps isolate queueing and severe outliers. |
How to Read This
If request volume is flat but latency jumps, suspect regression, resource contention, or dependency delays before assuming traffic surge.
Query 2: Slowest request paths¶
AppServiceHTTPLogs
| where TimeGenerated > ago(24h)
| summarize Requests=count(), P95=percentile(TimeTaken, 95), MaxTime=max(TimeTaken) by CsUriStem
| order by P95 desc
| take 15
| Column | Example data | Interpretation |
|---|---|---|
CsUriStem | /api/orders | Pinpoints the route driving the incident. |
P95 | 6400 | High path-specific latency supports H1. |
Requests | 22000 | High frequency plus high latency makes this path operationally dominant. |
How to Read This
A small set of expensive routes usually means application logic or dependency behavior is more important than platform-wide tuning.
Query 3: Restart and pressure correlation¶
AppServicePlatformLogs
| where TimeGenerated > ago(24h)
| where Message has_any ("Restarting", "ContainerTimeout", "OutOfMemory", "Stopping container", "recycle")
| project TimeGenerated, Level, Message
| order by TimeGenerated asc
| Column | Example data | Interpretation |
|---|---|---|
Message | Stopping container | Worker instability can explain sharp latency cliffs. |
Message | OutOfMemory | Strong evidence for H3 rather than H2. |
TimeGenerated | aligned to P95 spike | Correlation matters more than isolated restarts. |
How to Read This
Resource-pressure symptoms often show up first as latency and only later as explicit restarts. Build the timeline before tuning scale.
Query 4: Application Insights dependency latency (if enabled)¶
dependencies
| where timestamp > ago(24h)
| summarize Calls=count(), Failures=countif(success == false), P95=percentile(duration, 95) by target, type, bin(timestamp, 5m)
| order by timestamp asc
| Column | Example data | Interpretation |
|---|---|---|
target | sql-prod.database.windows.net | Isolates the downstream dependency under stress. |
Failures | 42 | Dependency instability can drive app latency with normal CPU. |
P95 | 00:00:03.2000000 | Elevated dependency duration supports H4. |
How to Read This
If dependency latency rises before HTTP latency, the app is probably waiting on something external rather than burning CPU locally.
Portal view: Application Insights Overview (where the query above runs)¶
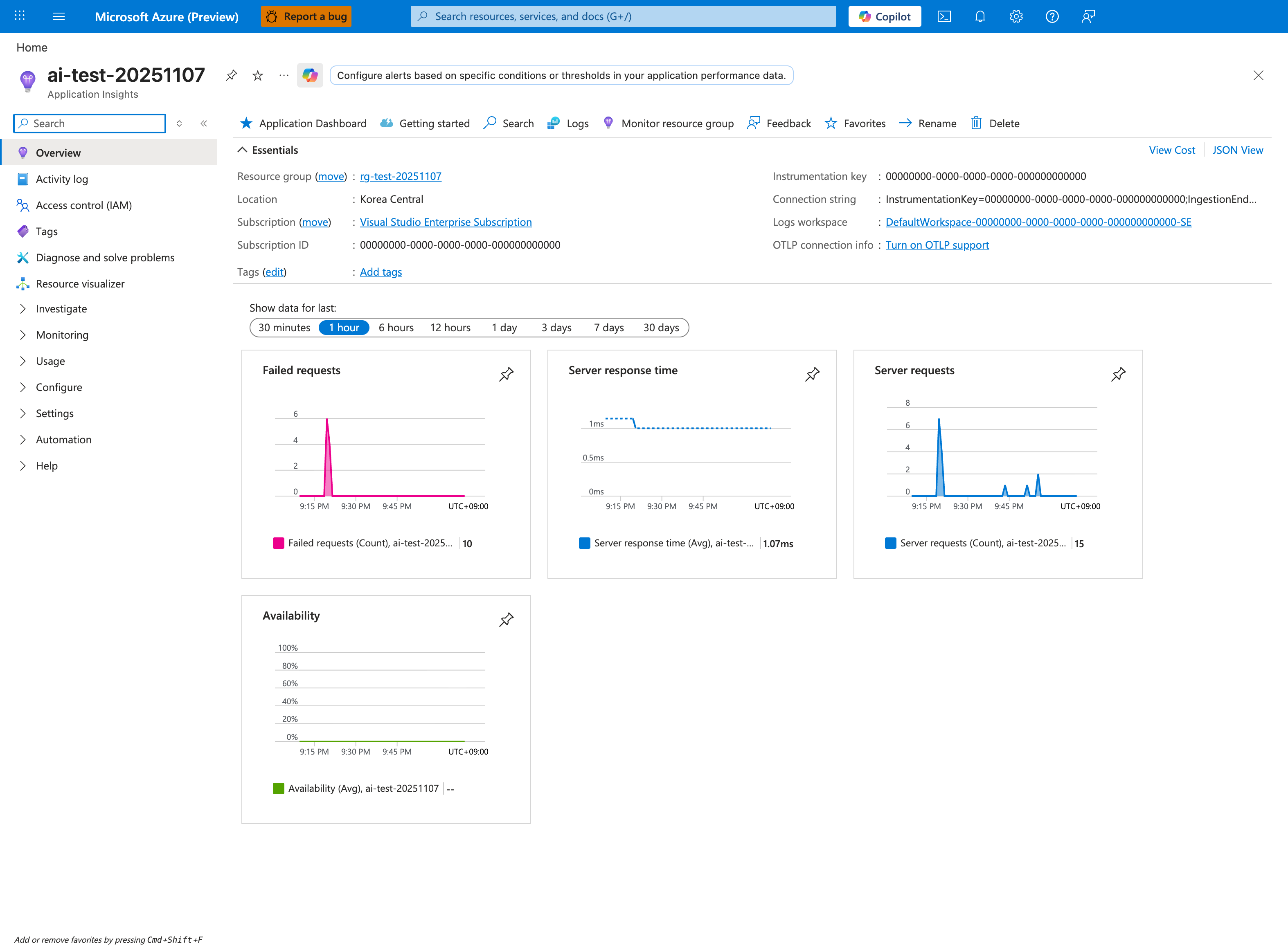
Application Insights is the most efficient surface for H4 (dependency hypothesis) because it correlates request latency with dependency duration in a single trace. The four Overview tiles give an immediate H1-vs-H4 read: a high Failed requests count with low Server response time points to fast-failing dependencies (H4), while a normal failure count with high server response time points to local processing (H1/H2). For the dependency KQL above, click Logs in the top toolbar to land in the Application Insights query editor where the dependencies table is queryable. Expand the Investigate group in the left nav and click Application Map for a visual dependency graph during triage - it surfaces failing downstream targets without writing KQL.
5.2 CLI Investigation¶
# Check plan capacity context
az appservice plan show \
--resource-group $RG \
--name $PLAN_NAME \
--query "{sku:sku.name,numberOfWorkers:numberOfWorkers,maximumElasticWorkerCount:maximumElasticWorkerCount}" \
--output json
Sample output:
Interpretation:
- Low worker count during sustained traffic supports H2, but only when logs also show load-driven degradation.
- Scale context alone never proves the app is the bottleneck.
# Show app configuration relevant to warm and steady-state performance
az webapp config show \
--resource-group $RG \
--name $APP_NAME \
--query "{alwaysOn:alwaysOn,http20Enabled:http20Enabled,appCommandLine:appCommandLine}" \
--output json
Sample output:
{
"alwaysOn": true,
"appCommandLine": "gunicorn --workers 4 --bind 0.0.0.0:8000 src.app:app",
"http20Enabled": true
}
Interpretation:
- This output helps distinguish configuration regressions from capacity issues.
- Compare worker/process configuration to the observed CPU and latency profile.
6. Validation and Disproof by Hypothesis¶
H1: One endpoint, query, or code path regressed¶
Proves if only a small set of URIs dominates P95/P99 latency or error increases.
Disproves if latency is uniform across nearly all routes and no path stands out.
Validation steps:
- Sort slowest paths by P95 and request count.
- Compare incident path set to the last known good release.
- Check whether one dependency or database call aligns only to those endpoints.
H2: CPU saturation or insufficient capacity¶
Proves if latency and errors rise with demand and scale context is tight.
Disproves if CPU remains modest while dependency latency or memory pressure explains the symptom better.
Validation steps:
- Correlate workload growth with the latency trend.
- Confirm the app is not simply blocked on external dependencies.
- Scale temporarily only to test the hypothesis, not as permanent proof.
H3: Memory pressure or worker degradation¶
Proves if restarts, recycling, or out-of-memory signatures align with latency growth.
Disproves if workers stay stable and no pressure signatures appear.
Validation steps:
- Review platform log restarts during the incident.
- Compare request latency before and after each restart.
- Use existing memory-focused playbooks if the pattern is confirmed.
H4: Downstream dependency or outbound issue¶
Proves if dependency latency/failure rises before or during app latency while local CPU remains lower.
Disproves if no dependency trend is visible and local resource pressure dominates.
Validation steps:
- Check Application Insights dependencies or route-specific downstream errors.
- If outbound networking is suspected, compare with SNAT/DNS playbooks.
- Validate whether retries amplify latency.
7. Likely Root Cause Patterns¶
| Pattern | Evidence | Resolution |
|---|---|---|
| Hot endpoint regression | One route dominates slow-path query | Optimize code path, cache strategy, or backing query. |
| CPU-bound worker pool | Rising latency with heavy compute and tight worker count | Tune concurrency and scale appropriately. |
| Memory churn or leak | Gradual slowdown followed by recycle | Reduce allocation pressure and right-size the plan. |
| Slow dependency | App latency tracks dependency P95 and failures | Fix downstream bottleneck or retry strategy. |
| Post-release configuration change | Incident starts immediately after deployment | Revert or compare config drift against last good state. |
8. Immediate Mitigations¶
- If a release triggered the issue, consider rollback before broad tuning changes.
- Reduce pressure by scaling out temporarily if the app is still serving traffic.
- Disable or rate-limit the worst offender endpoint if one route is dominating the outage.
- Short-circuit expensive startup or background tasks that run on every worker recycle.
- If dependency latency is dominant, reduce retries and timeouts that amplify queueing.
- Re-collect latency evidence after each change and stop once user-facing latency returns to baseline.
9. Prevention¶
Prevention checklist¶
- [ ] Track P50, P95, P99, error rate, and dependency latency for every production app.
- [ ] Load-test hot endpoints before major releases.
- [ ] Keep staging or canary validation for new builds and config changes.
- [ ] Monitor memory and restart patterns, not just average CPU.
- [ ] Maintain clear SLO-based alerts for latency and failure rate.
See Also¶
- Playbooks
- Slow Response but Low CPU
- Memory Pressure and Worker Degradation
- Intermittent 5xx Under Load