SNAT or Application Issue? (Azure App Service Linux)¶
1. Summary¶
Symptom¶
Outbound calls from the App Service app intermittently fail with timeouts or connection errors. The app can reach some external endpoints but fails on others, or failures appear under load but not during light traffic.
Why this scenario is confusing¶
SNAT port exhaustion and application-level timeout/connection bugs produce nearly identical symptoms: intermittent outbound failures. Engineers often cannot tell whether the platform (SNAT) or the app (connection handling) is at fault.
Troubleshooting decision flow¶
graph TD
A[Symptom: Intermittent outbound timeout/connection errors] --> B{Check SNAT detector first}
B --> C[Near 128 preallocated ports per instance]
B --> D[SNAT healthy during failures]
C --> H1[H1: SNAT port exhaustion]
D --> E{What error signatures dominate?}
E --> F[Pool/connection lifecycle or blocking patterns]
E --> G[ENOTFOUND or name-resolution failures]
E --> I[Only specific dependency endpoints degrade]
F --> H2[H2: Application connection management bug]
G --> H3[H3: DNS resolution failure]
I --> H4[H4: Downstream dependency issue]Scope and limitations¶
- Windows-specific SNAT behavior is out of scope.
- This playbook does not cover ASE (App Service Environment) specific networking.
- Detailed framework-specific connection pooling configuration is referenced but not exhaustively documented.
Quick conclusion¶
Start by proving or disproving SNAT with the SNAT Port Exhaustion and TCP Connections detectors before changing code or scaling strategy. If SNAT is not near exhaustion, treat the incident as an application or dependency reliability problem and validate connection pooling, DNS behavior, and downstream health in parallel. In Azure App Service Linux, the fastest durable outcome is usually client connection reuse plus Private Endpoints and NAT Gateway where appropriate.
2. Common Misreadings¶
- "Outbound calls fail, so it must be a networking issue"
- "We're not making that many connections, so SNAT can't be the issue"
- "It works sometimes, so the network path is fine"
- "Adding more instances will fix it" (scale-out adds per-instance SNAT pools but does not fix bad connection patterns — the root cause persists and may mask the problem temporarily)
3. Competing Hypotheses¶
- H1: SNAT port exhaustion — app creates too many short-lived outbound connections without reuse, exceeding the 128 preallocated SNAT ports per instance.
- H2: Application connection management bug — connection pool exhaustion, not closing HttpClient/connections, synchronous blocking.
- H3: DNS resolution failure — VNet-integrated app cannot resolve private DNS, or DNS TTL caching issues.
- H4: Downstream dependency issue — the target service is slow/down, causing connection queue buildup that looks like SNAT.
4. What to Check First¶
Metrics¶
- SNAT Port Exhaustion detector in App Service Diagnostics.
- TCP Connections metric.
- Outbound connection count per instance.
Logs¶
- AppServiceConsoleLogs: look for "connection refused", "timeout", "SNAT" messages.
- AppServiceHTTPLogs: correlate slow/failed requests with outbound dependency endpoints.
Platform Signals¶
- SNAT Port Exhaustion detector.
- TCP Connections detector.
- VNet integration status (if applicable).
- NAT Gateway configuration (if applicable).
Portal view: Networking blade for SNAT-bypass topology verification¶
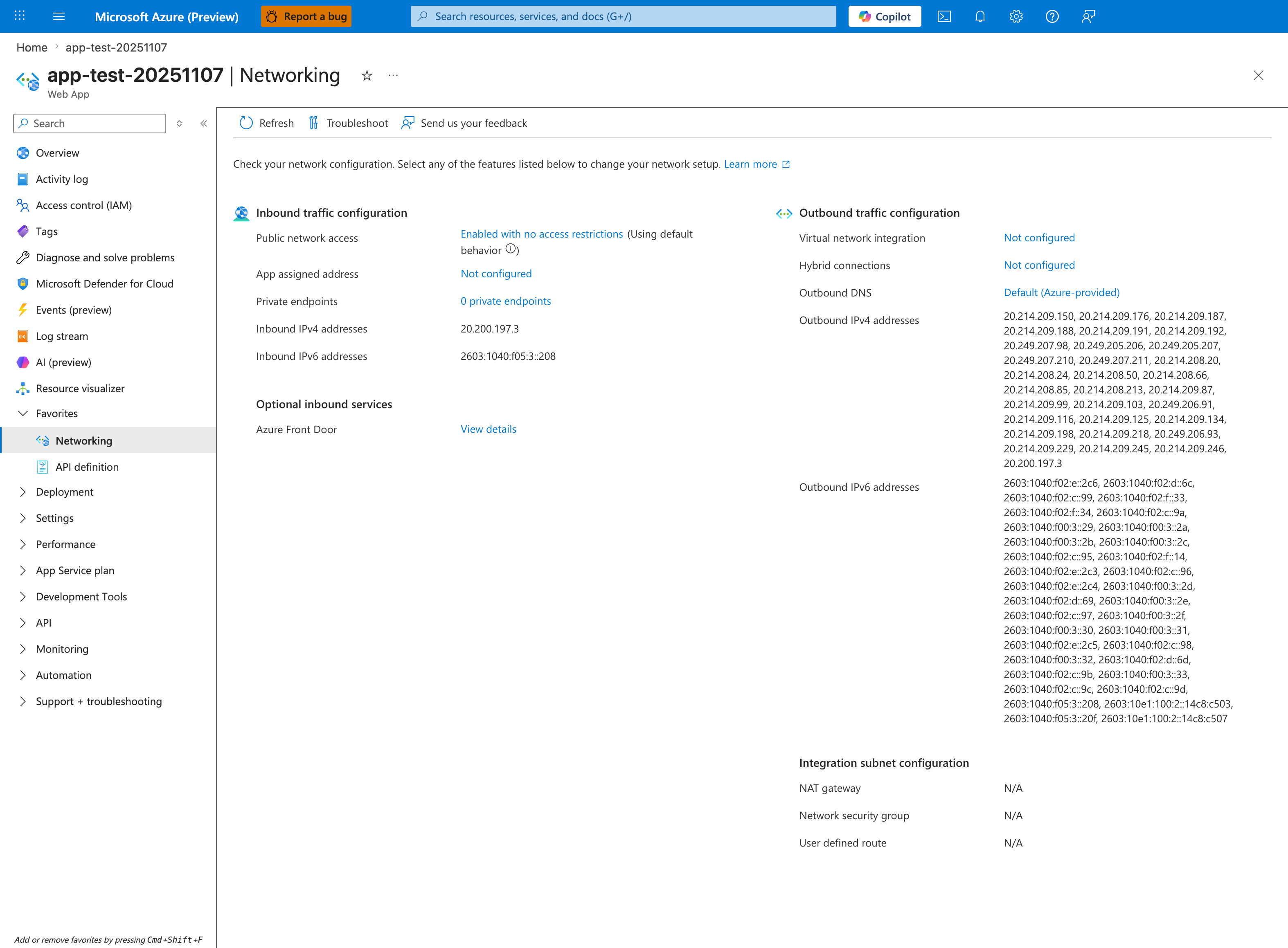
The Networking blade is the single source of truth for whether the app is using SNAT bypass mechanisms (NAT Gateway, Private Endpoints to dependencies) that this playbook recommends as the durable fix for H1. The Outbound traffic configuration column shown above reveals an apartment-style baseline: Virtual network integration: Not configured and (implied from that) NAT gateway: N/A mean every outbound call from this app shares the default per-instance pool of 128 preallocated SNAT ports — the exact constraint that causes the timeout-cluster signature documented in Section 5. If Virtual network integration shows a subnet ID and the Integration subnet configuration card reports NAT gateway: <name>, SNAT is bypassed for traffic flowing through that NAT Gateway's port pool (~64,000 ports per public IP). Click Virtual network integration to inspect or configure the subnet, then verify Private Endpoint targets in the Inbound traffic configuration > Private endpoints link (though for SNAT bypass, the relevant Private Endpoints are on the dependency resources, not on the App Service itself).
Investigation Notes¶
- SNAT applies only to outbound connections to PUBLIC IP addresses. Private Endpoint and Service Endpoint traffic does NOT consume SNAT ports.
- 128 SNAT ports per instance is the preallocated amount; Azure may dynamically allocate more, but don't rely on it.
- NAT Gateway provides 64,000 SNAT ports per public IP, shared across all instances.
- Connection reuse is the single most impactful fix.
- Python: use requests.Session() or httpx.Client() for connection pooling. Do NOT create new requests.get() for every call.
- Node.js: use keep-alive agents. Default http.Agent does not enable keep-alive.
5. Evidence to Collect¶
Required Evidence¶
- SNAT port allocation timeline from diagnostics.
- TCP connection count over time.
- Application-level connection pool configuration.
- Outbound call patterns (how many unique destination IP:port combinations).
Useful Context¶
- Whether app uses connection pooling (HttpClient reuse, database connection pooling).
- VNet integration settings.
- NAT Gateway presence.
- Private Endpoint configuration for dependencies.
- Recent scale-out events (more instances = more SNAT demand if patterns are bad).
Sample Log Patterns¶
AppServiceHTTPLogs (snat-exhaustion lab)¶
[AppServiceHTTPLogs]
2026-04-04T11:24:40Z GET /diag/env 200 36786
2026-04-04T11:24:03Z GET /diag/stats 499 59709
2026-04-04T11:22:20Z GET /outbound 499 29840
2026-04-04T11:22:20Z GET /outbound 499 29834
2026-04-04T11:22:20Z GET /outbound 499 29830
2026-04-04T11:22:20Z GET /outbound 499 29819
2026-04-04T11:22:20Z GET /outbound 499 29820
2026-04-04T11:22:20Z GET /outbound 499 29786
AppServiceConsoleLogs (snat-exhaustion lab)¶
[AppServiceConsoleLogs]
2026-04-04T11:14:18Z Error [2026-04-04 11:14:18 +0000] [1896] [INFO] Control socket listening at /root/.gunicorn/gunicorn.ctl
2026-04-04T11:14:17Z Error [2026-04-04 11:14:17 +0000] [1900] [INFO] Booting worker with pid: 1900
2026-04-04T11:14:17Z Error [2026-04-04 11:14:17 +0000] [1899] [INFO] Booting worker with pid: 1899
2026-04-04T11:14:17Z Error [2026-04-04 11:14:17 +0000] [1898] [INFO] Booting worker with pid: 1898
2026-04-04T11:14:17Z Error [2026-04-04 11:14:17 +0000] [1897] [INFO] Booting worker with pid: 1897
2026-04-04T11:14:17Z Error [2026-04-04 11:14:17 +0000] [1896] [INFO] Using worker: sync
2026-04-04T11:14:17Z Error [2026-04-04 11:14:17 +0000] [1896] [INFO] Listening at: http://0.0.0.0:8000 (1896)
2026-04-04T11:14:17Z Error [2026-04-04 11:14:17 +0000] [1896] [INFO] Starting gunicorn 25.3.0
AppServicePlatformLogs (snat-exhaustion lab)¶
[AppServicePlatformLogs]
2026-04-04T11:14:47Z Informational Site: <app-name> stopped.
2026-04-04T11:14:47Z Informational Container is terminated. Total time elapsed: 5648 ms.
2026-04-04T11:14:41Z Informational State: Stopping, Action: StoppingSiteContainers
How to Read This
Repeated /outbound 499 responses near ~30 seconds indicate client-side timeout/disconnect under outbound pressure. Combined with sync Gunicorn workers, requests block worker slots while outbound connections stall.
KQL Queries with Example Output¶
Query 1: Outbound endpoint timeout signature¶
AppServiceHTTPLogs
| where TimeGenerated between (datetime(2026-04-04 11:22:00) .. datetime(2026-04-04 11:25:00))
| where CsUriStem in ("/outbound", "/diag/stats", "/diag/env")
| project TimeGenerated, CsMethod, CsUriStem, ScStatus, TimeTaken
| order by TimeGenerated desc
Example Output:
| TimeGenerated | CsMethod | CsUriStem | ScStatus | TimeTaken |
|---|---|---|---|---|
| 2026-04-04 11:24:40 | GET | /diag/env | 200 | 36786 |
| 2026-04-04 11:24:03 | GET | /diag/stats | 499 | 59709 |
| 2026-04-04 11:22:20 | GET | /outbound | 499 | 29840 |
| 2026-04-04 11:22:20 | GET | /outbound | 499 | 29834 |
| 2026-04-04 11:22:20 | GET | /outbound | 499 | 29786 |
How to Read This
The tight cluster of /outbound 499 around ~29.8-29.9 seconds is a classic timeout boundary signature. This supports connection pressure/SNAT or blocked worker behavior more than random downstream app exceptions.
Query 2: Worker model evidence from console logs¶
AppServiceConsoleLogs
| where TimeGenerated between (datetime(2026-04-04 11:14:00) .. datetime(2026-04-04 11:15:00))
| project TimeGenerated, Level, ResultDescription
| order by TimeGenerated asc
Example Output:
| TimeGenerated | Level | ResultDescription |
|---|---|---|
| 2026-04-04 11:14:17 | Error | [INFO] Starting gunicorn 25.3.0 |
| 2026-04-04 11:14:17 | Error | [INFO] Listening at: http://0.0.0.0:8000 (1896) |
| 2026-04-04 11:14:17 | Error | [INFO] Using worker: sync |
| 2026-04-04 11:14:17 | Error | [INFO] Booting worker with pid: 1897 |
| 2026-04-04 11:14:17 | Error | [INFO] Booting worker with pid: 1898 |
| 2026-04-04 11:14:17 | Error | [INFO] Booting worker with pid: 1899 |
| 2026-04-04 11:14:17 | Error | [INFO] Booting worker with pid: 1900 |
How to Read This
Four sync workers means each slow outbound call can pin a worker until timeout. Under connection pressure, worker exhaustion amplifies user-visible latency and 499 rates.
Query 3: Platform lifecycle sanity check¶
AppServicePlatformLogs
| where TimeGenerated between (datetime(2026-04-04 11:14:35) .. datetime(2026-04-04 11:14:50))
| project TimeGenerated, Level, Message
| order by TimeGenerated asc
Example Output:
| TimeGenerated | Level | Message |
|---|---|---|
| 2026-04-04 11:14:41 | Informational | State: Stopping, Action: StoppingSiteContainers |
| 2026-04-04 11:14:47 | Informational | Container is terminated. Total time elapsed: 5648 ms. |
| 2026-04-04 11:14:47 | Informational | Site: |
How to Read This
These rows confirm lifecycle events but do not explain timeout clusters by themselves. Root-cause signal is primarily in /outbound timeout pattern plus worker model and SNAT detector evidence.
CLI Investigation Commands¶
# Check app worker/process-relevant settings
az webapp config show --resource-group <resource-group> --name <app-name> --query "{linuxFxVersion:linuxFxVersion,appCommandLine:appCommandLine,alwaysOn:alwaysOn}" --output table
# Inspect app settings commonly tied to outbound pressure behavior
az webapp config appsettings list --resource-group <resource-group> --name <app-name> --query "[?name=='WEBSITES_PORT' || name=='WEBSITE_VNET_ROUTE_ALL' || name=='PYTHON_GUNICORN_CUSTOM_THREAD_NUM' || name=='PYTHON_VERSION'].{name:name,value:value}" --output table
# Confirm VNet integration and route-all posture (needed for NAT Gateway/PE architecture)
az webapp show --resource-group <resource-group> --name <app-name> --query "{virtualNetworkSubnetId:virtualNetworkSubnetId,vnetRouteAllEnabled:siteConfig.vnetRouteAllEnabled}" --output table
# Check recent app restart timeline
az webapp show --resource-group <resource-group> --name <app-name> --query "{state:state,lastModifiedTimeUtc:lastModifiedTimeUtc}" --output table
Example Output:
LinuxFxVersion AppCommandLine AlwaysOn
---------------- -------------------------------------------------- --------
PYTHON|3.11 gunicorn --bind 0.0.0.0:8000 --workers 4 app:app True
Name Value
------------------ -----
WEBSITES_PORT 8000
PYTHON_VERSION 3.11
VirtualNetworkSubnetId VnetRouteAllEnabled
---------------------------------------------------------------------------------------------------------------------------- -------------------
/subscriptions/<subscription-id>/resourceGroups/<resource-group>/providers/Microsoft.Network/virtualNetworks/<vnet>/subnets/<subnet> true
How to Read This
This confirms runtime shape (4 sync workers) and networking posture. Correlate with SNAT detector trends: if ports are saturated during /outbound spikes, H1 dominates; if not, H2 (application connection pattern) dominates.
6. Validation and Disproof by Hypothesis¶
H1: SNAT port exhaustion¶
Signals that support - SNAT Port Exhaustion detector shows instances frequently at or near the preallocated 128 ports during incident windows. - TCP Connections rises sharply on affected instances, and failures begin when connection churn increases (for example, traffic spikes or batch jobs). - AppServiceConsoleLogs show outbound socket creation/connection timeout errors concentrated around the same timestamps as high SNAT utilization. - Failures are most visible for public endpoints (internet or public PaaS FQDNs), while Private Endpoint traffic remains healthy.
Signals that weaken - Detector shows low SNAT utilization with ample available ports during failures. - Failures occur even at low traffic with stable connection counts and no connection churn. - Only one dependency FQDN fails consistently while other outbound dependencies are unaffected.
What to verify
- In App Service Diagnostics, open SNAT Port Exhaustion and inspect per-instance trends over the failure timeframe.
- Open the TCP Connections detector and compare connection count behavior to error timestamps.
- Query AppServiceConsoleLogs for connection timeout/refused patterns and correlation in time:
AppServiceConsoleLogs
| where TimeGenerated > ago(6h)
| where ResultDescription has_any ("timeout", "timed out", "connection refused", "ECONNRESET", "SNAT")
| project TimeGenerated, _ResourceId, ResultDescription
| order by TimeGenerated desc
H2: Application connection management bug¶
Signals that support - SNAT Port Exhaustion detector is not near limits, but outbound failures continue. - Errors include pool starvation patterns (for example, HTTP client pool exhausted, max connections reached, task/thread starvation). - Code paths create new outbound client objects per request (for example, per-call HttpClient, per-call requests usage without Session reuse). - Latency grows before outright failures, consistent with queueing inside the app runtime rather than immediate network rejection.
Signals that weaken - Clear SNAT saturation on the same instance/time window as errors. - After enabling client reuse/keep-alive, no measurable change in error rate. - Identical requests from a test workload succeed consistently while production only fails at DNS resolution stage.
What to verify
- Review application code and DI/container lifetime for outbound clients (singleton/shared client expected for most HTTP SDKs).
- Inspect runtime logs for pool and socket lifecycle errors in AppServiceConsoleLogs.
- Use AppServiceHTTPLogs to map high-latency responses to handlers that invoke outbound calls:
AppServiceHTTPLogs
| where TimeGenerated > ago(6h)
| summarize Requests=count(), P95DurationMs=percentile(TimeTaken, 95), Failures=countif(ScStatus >= 500)
by bin(TimeGenerated, 5m), CsUriStem
| order by TimeGenerated desc
H3: DNS resolution failure¶
Signals that support - Error text is resolution-specific (Name or service not known, ENOTFOUND, Temporary failure in name resolution) rather than connect timeout after DNS success. - Failures cluster to hostname-based endpoints; direct IP tests succeed. - VNet-integrated app recently changed custom DNS settings, private DNS zone links, or forwarder configuration. - Incidents are intermittent around TTL boundaries or resolver instability rather than strictly load-linked.
Signals that weaken - Errors are socket/connect timeout to resolved IPs, with no resolver error signatures. - nslookup for affected hostnames from the app sandbox consistently returns expected records. - Private Endpoint names resolve and connect reliably while only high-RPS paths fail.
What to verify
- From Kudu/SSH on the Linux app container, run
nslookup <hostname>repeatedly for affected dependencies. - Validate App Service VNet integration and DNS server settings (custom DNS IPs, route reachability, private DNS zone links).
- Query AppServiceConsoleLogs for resolution-specific strings:
AppServiceConsoleLogs
| where TimeGenerated > ago(6h)
| where ResultDescription has_any ("ENOTFOUND", "name resolution", "Name or service not known", "DNS")
| project TimeGenerated, _ResourceId, ResultDescription
| order by TimeGenerated desc
H4: Downstream dependency issue¶
Signals that support - One or a small set of dependencies show increased latency/5xx while others remain healthy from the same app instance. - Independent telemetry from the dependency confirms degradation during the same period. - Retries/circuit-breaker logs show repeated remote failures (HTTP 429/5xx, upstream timeout) after connection establishment. - Synthetic checks from outside App Service also fail or degrade against the same endpoint.
Signals that weaken - All outbound dependencies degrade at once in proportion to connection churn. - Dependency health dashboards show normal latency/error rates while only this app reports failures. - Failures disappear immediately after reducing local connection churn without any downstream change.
What to verify
- Compare AppServiceHTTPLogs failure windows to dependency-side health dashboards/APM traces.
- Run external synthetic probes (for example, from another Azure host) to confirm if dependency slowness reproduces.
- Segment logs by dependency endpoint in application logs and check whether failure distribution is endpoint-specific.
Normal vs Abnormal Comparison¶
| Signal | Normal outbound behavior | Abnormal (snat-exhaustion lab pattern) |
|---|---|---|
/outbound status | Mostly 200 with moderate latency | Burst of 499 responses |
/outbound TimeTaken | Variable, generally below timeout boundary | Tight cluster near ~29,786-29,840 ms (timeout boundary) |
| Worker model impact | Workers free quickly; queue stable | Sync workers held by slow outbound calls, queue grows |
/diag/stats health | 200 with low latency | 499 up to ~59,709 ms under pressure |
| SNAT detector expectation | Ports below pressure threshold | Ports near/exceed threshold during incidents |
| Interpretation | Healthy dependency + connection lifecycle | Outbound connection pressure (SNAT and/or app connection management) |
7. Likely Root Cause Patterns¶
- Pattern A: New HttpClient per request (classic .NET anti-pattern, also applies to Python requests.Session not reused).
- Pattern B: Connection pool too small for traffic volume.
- Pattern C: Synchronous outbound calls blocking threads, causing connection queue backup.
- Pattern D: Scale-out without fixing connection patterns (more instances provide additional per-instance SNAT pools, but the underlying connection anti-pattern persists and may resurface under higher load).
8. Immediate Mitigations¶
- Enable connection pooling / reuse existing clients (diagnostic, production-safe).
- Reduce outbound connection creation rate (diagnostic, production-safe).
- Add NAT Gateway for dedicated outbound IP and larger port pool (temporary/permanent, production-safe).
- Use Private Endpoints for Azure dependencies to bypass SNAT entirely (permanent, production-safe).
- Use NAT Gateway for dedicated outbound IP and expanded port pool if SNAT pressure is per-instance (permanent, production-safe, requires VNet integration).
9. Prevention¶
- Implement proper connection pooling across all outbound clients.
- Use Private Endpoints for all Azure PaaS dependencies.
- Add NAT Gateway for non-Azure outbound traffic.
- Implement circuit breaker pattern for dependency calls.
- Monitor SNAT usage as a standard operational metric.
See Also¶
../../kql/http/latency-trend-by-status-code.md../../kql/correlation/latency-vs-errors.md../../first-10-minutes/outbound-network.md- Lab: SNAT Exhaustion
- Outbound Network (First 10 Minutes)
- SNAT Exhaustion Lab